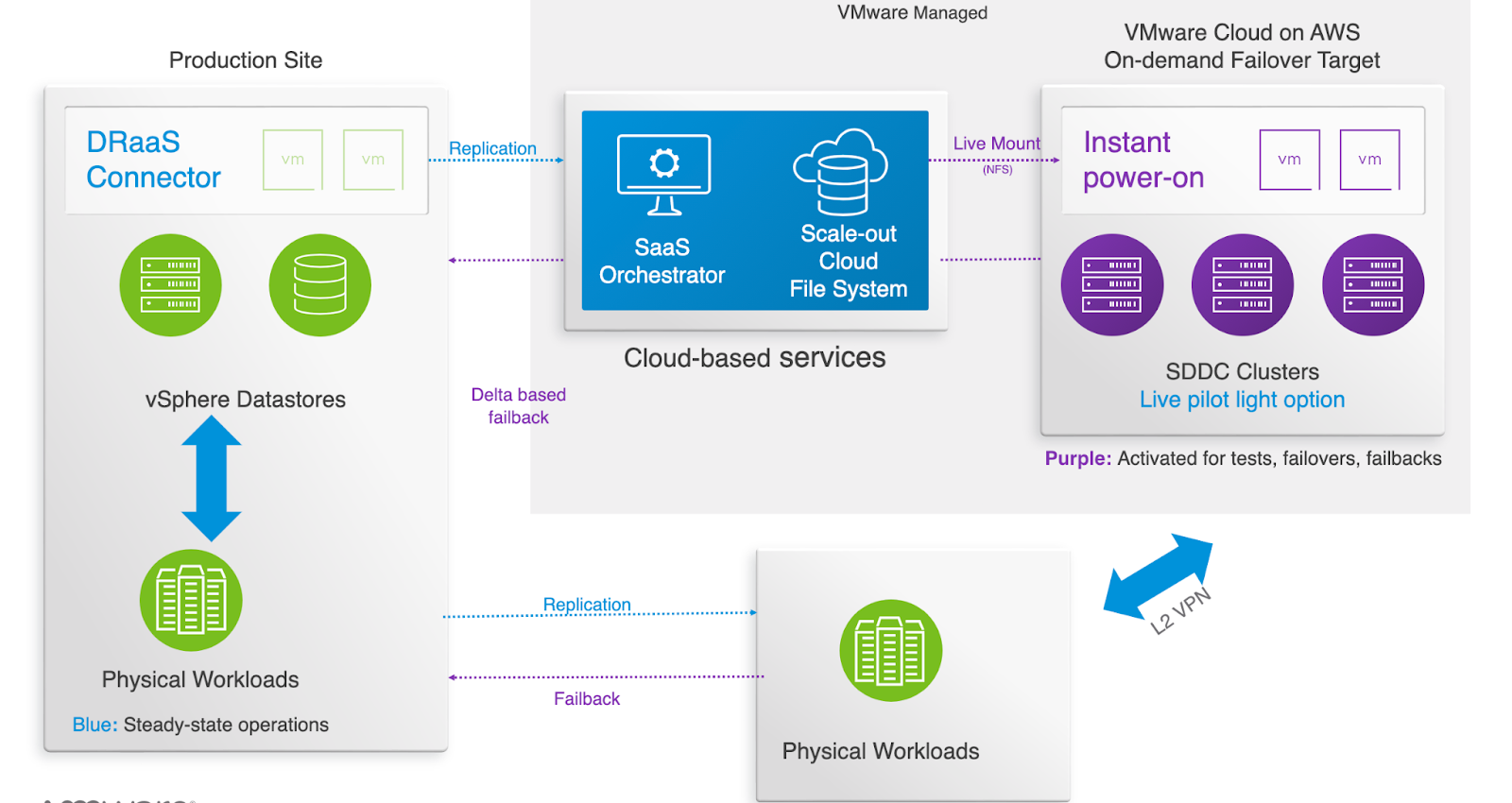
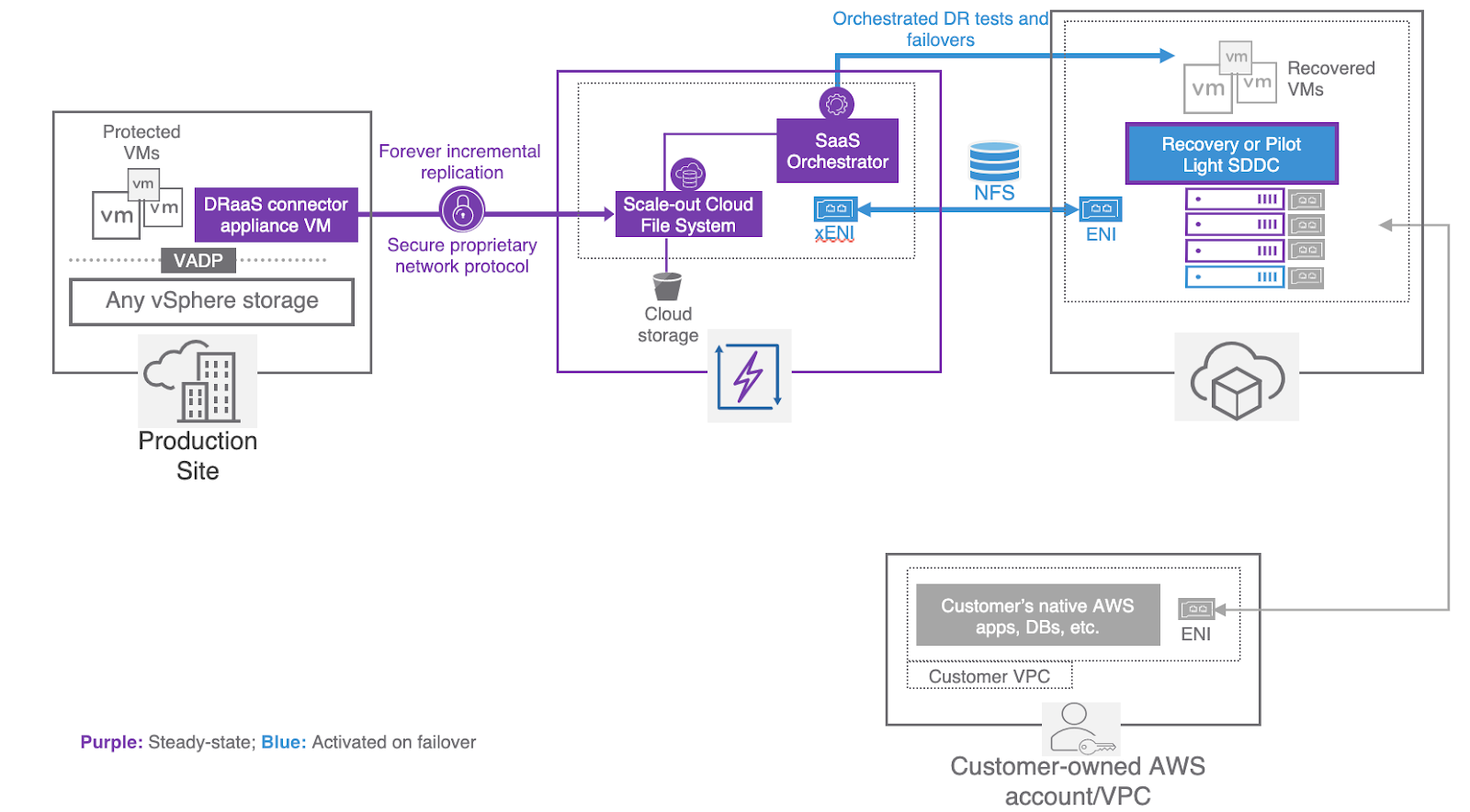
I generally try to write about what I am working on at any given time. This month has involved working on connecting applications which have a hard requirement to span Layer 2 from the VMware Cloud on AWS environment to a customers on premises datacenter. While I normally try to bring sanity to these environments and push for a refactoring/replatforming exercise, for may of the teams I assist, this is just not an option, or is a long term project. Part of the value of VMC on AWS is the flexibility of the solution while bringing environments closer to cloud native resources.
Design requirements
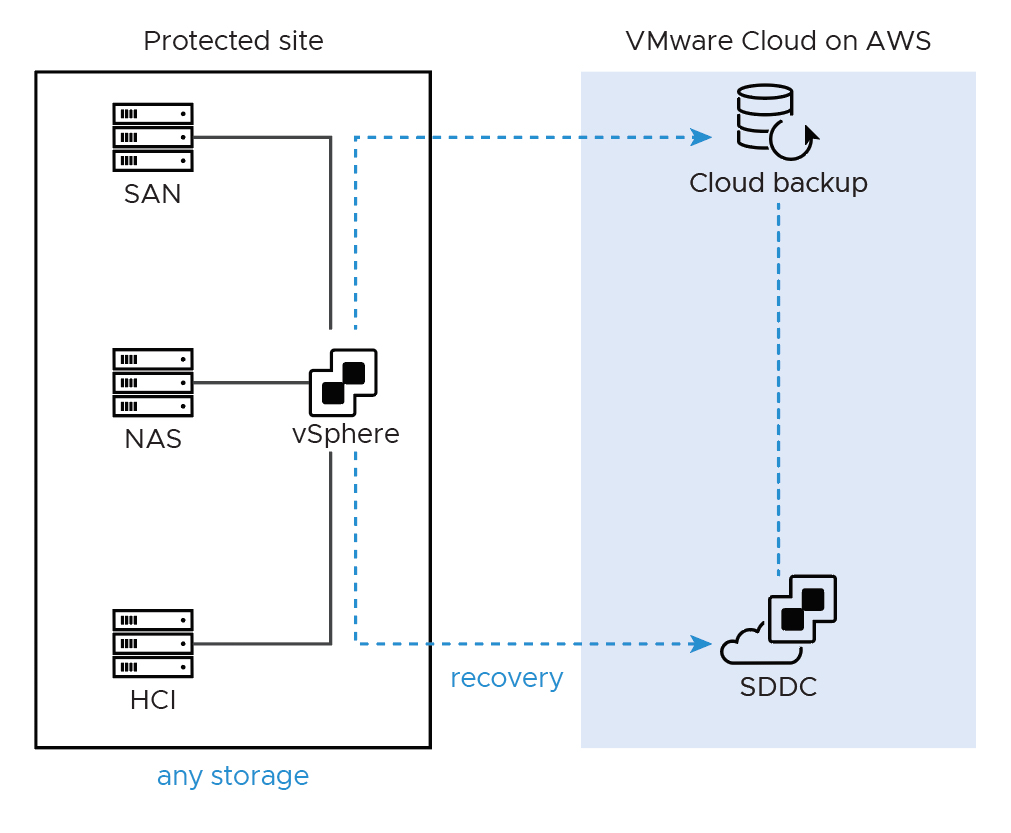
For this particular use case we were working to connect a single non-x86 system running a database to the VMC environment, with no opportunity to migrate/convert the database to something we could run in VMC or a native cloud provider. Since this is business continuity design exercise, every attempt must be made to mirror production. All x86 virtual systems will be replicated to the VMC environment, and the remaining system will sit in a co-location datacenter in the same region. Connectivity between the VMC environment and the co-location datacenter is accomplished by a direct connect which is assumed to be connected already..
Setting up the VMC environment.
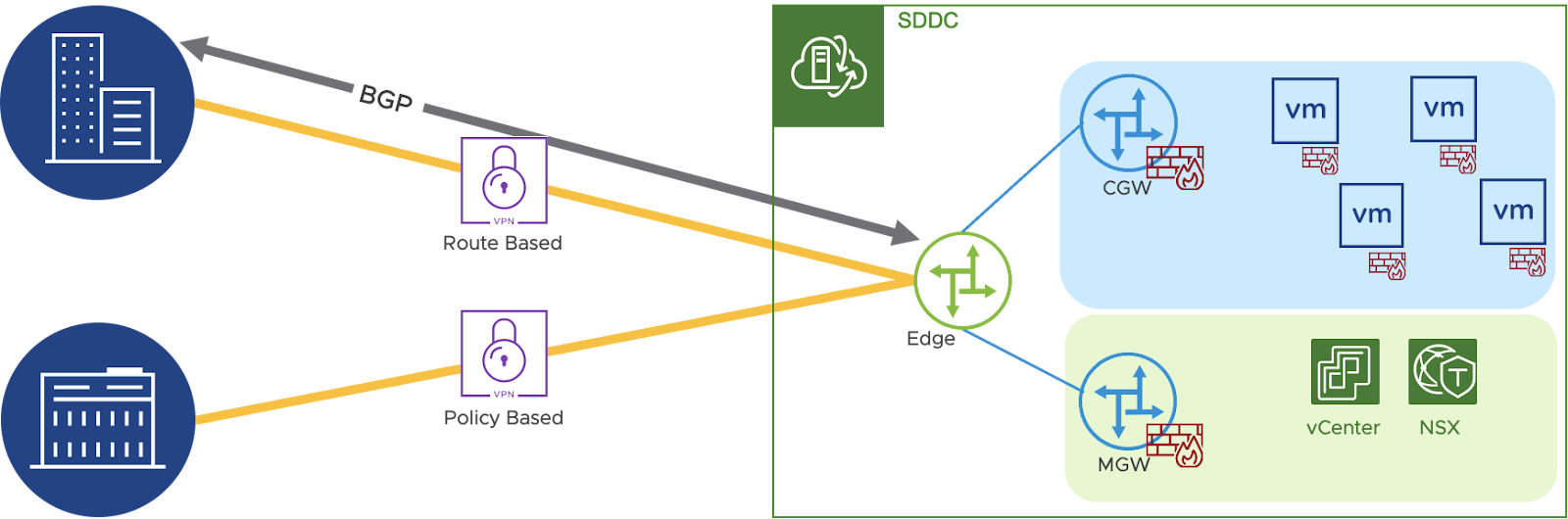
Once logged into the VMC on AWS environment, select “View Details” on the SDDC to be connected to. Under the “Networking & Security” Tab, select “VPN” and then “Layer 2”. Select “Add VPN Tunnel”. In this case since we are going over a direct connect we chose the provided Private IP address, and our remote public IP was the termination of the direct connect at the colo.

After saving, expand the VPN and download the config, you will need this soon. You will also want to take note of the “Local IP Address” for the VMC environment. This can be obtained by clicking the info icon, and then copy the Local Gateway IP (Blocked here for security).

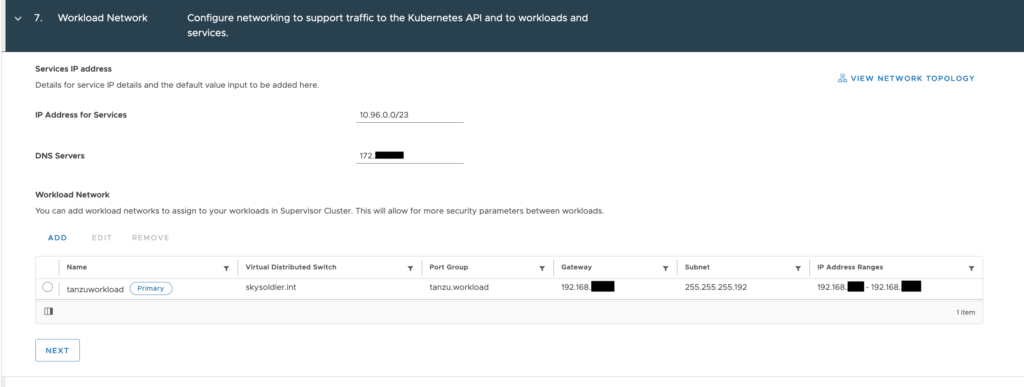
Next select “Segments” in the left panel and “Add Segment”. Enter a segment name that will make sense for the environment, set type to “Extended”, and select a tunnel ID, it must be unique to the extended segments in your VMC SDDC.

NSX Edge deployment on-prem/colo
The remaining work will be done from the local or colo vcenter server. Download the NSX-T Datacenter OVA, and begin the deploy process to your local vCenter.
Select Networks
At the “Select Networks” section, you need to determine your network topology. In this case we are running VLAN’s on the dvSwitch, so each port is treated as an access port. This becomes critical in the next screen. For the sake of simplicity I have labeled the Port Groups as what they are used for.
Network 0 – For accessing the OVA’s cli and web management interface.
Network 1 – The management interface for the VPN.
Network 2 – This is the network where the layer 2 traffic will flow.
Network 3 – This is for HA traffic if you are running multiple edges for redundancy, not used in this case but still required.

Customize Template
Put in passwords and usernames as required until you come to the Manager area. There is no NSX manager since we are deploying as an autonomous edge so skip everything except make sure you put a check in the Autonomous Edge.
Under network properties enter a hostname, and the management IP information. This should be an IP on the Management network as above.

In the External section, as stated above, we are using VLANs at the portgroup level which effectively makes the port an access port, so in the box we need to make sure we set the VLAN to 0 and complete as below. This is our uplink configuration so make sure you select eth1 in this case.

Ignore Internal and HA sections and the rest of the inputs, and select next, review, and then finish to deploy.
Configure the Autonomous Edge and Tunnel
When the NSX Autonomous edge has finished deploying, bring up the web interface and login as admin. Select L2VPN and ADD SESSION, and fill in the fields.
Session Name – Input a name that makes sense.
Admin Status – Leave as Enabled.
Local IP – The external uplink IP we previously gave when installing the Autonomous Edge.
Remote IP – The Local Gateway IP we previously obtained from the VMC Environment.
Peer Code – This is found in the config file we previously downloaded, paste the text here.

Save and select PORT and Add Port, and fill in the fields
Port Name – Input a name that makes sense (This is for the trunk so likely include that)
Subnet – Leave this blank
VLAN – 0 (Remember we are terminating the VLAN’s at the port group so these are access ports)
Exit Interface – eth2 (our trunk port)

Save and return to the L2VPN screen and select ATTACH PORT.
Session – Select the session we created previously
Port – Select the Port we just created.
Tunnel ID – this is the same as the Tunnel ID we created on the VMC on AWS side.

Once you attach the status should come up on both ends, and you are now connected. For test purposes it is usually wise to put a test machine on each end of the tunnel, and run a few network tests. This is not as common a use case, but it is helpful for environments where L2 tunneling is required.
For more information please look at the documentation VMware publishes and the blog post I used as well while working on the solution.
VMware Documentation
Configure an Extended Segment for the Layer 2 VPN
Install and Configure the On-Premises NSX Edge