Previously I talked about VCDR (VMware Cloud Disaster Disaster Recovery) Solutions Validation, and how to properly run a proof of concept. The reality is that while it would be nice if all applications were as straightforward as our wordpress example, there are often far more complex applications requiring far more advanced designs for a disaster recovery plan to be successful.
External Network Dependencies
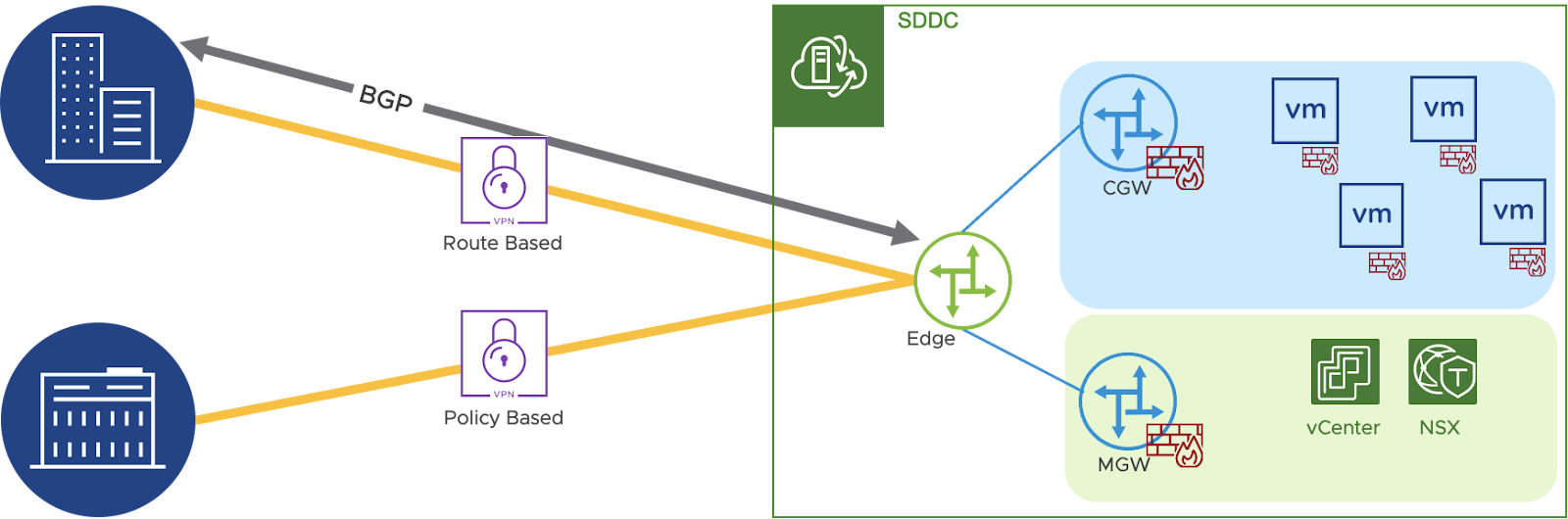
For many applications, even in modern datacenters, external network dependencies, or even Virtual Machines which are too large for traditional replication solutions can create challenges when creating disaster recovery plans.
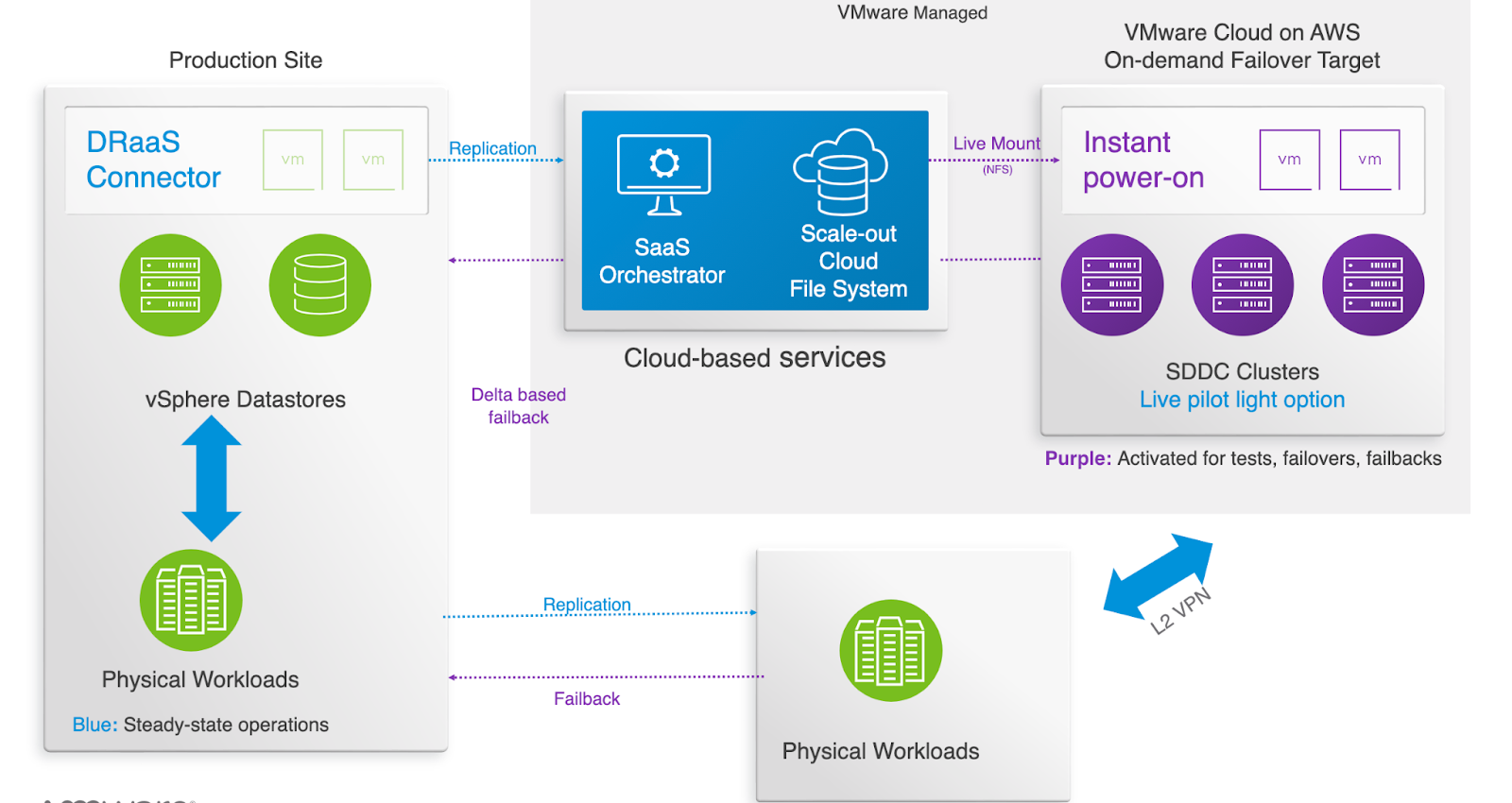
To solve for this, 3rd party partners may be used to provide array or other host based replication services. This solution requires far more effort on the part of the managed services partner, or the DR Admin. Since the physical or too large for VCDR workloads cannot be orchestrated through the traditional SaaS orchestrator, there is an additional requirement to both test, and manually failing over. A Layer 2 VPN between the VMware Cloud Environment and the partner location provides the connectivity for the applications running in both environments.
Script VM
For the more complex VM only environments, some scripts may need to be run during the test and recovery phases.Similar to bootstrap scripts for operating system provisioning, the scripts may be used for basic or even more advanced configuration changes.
The script VM should be an administrative or management server which is either the first VM started in the test recovery, or production recovery plans. Separate VMs may be designated for testing versus production recovery as well, enabling further isolated testing one of the biggest value propositions of the solution. Further specific documentation is located here, Configure Script VM.

Extending into VMC on AWS
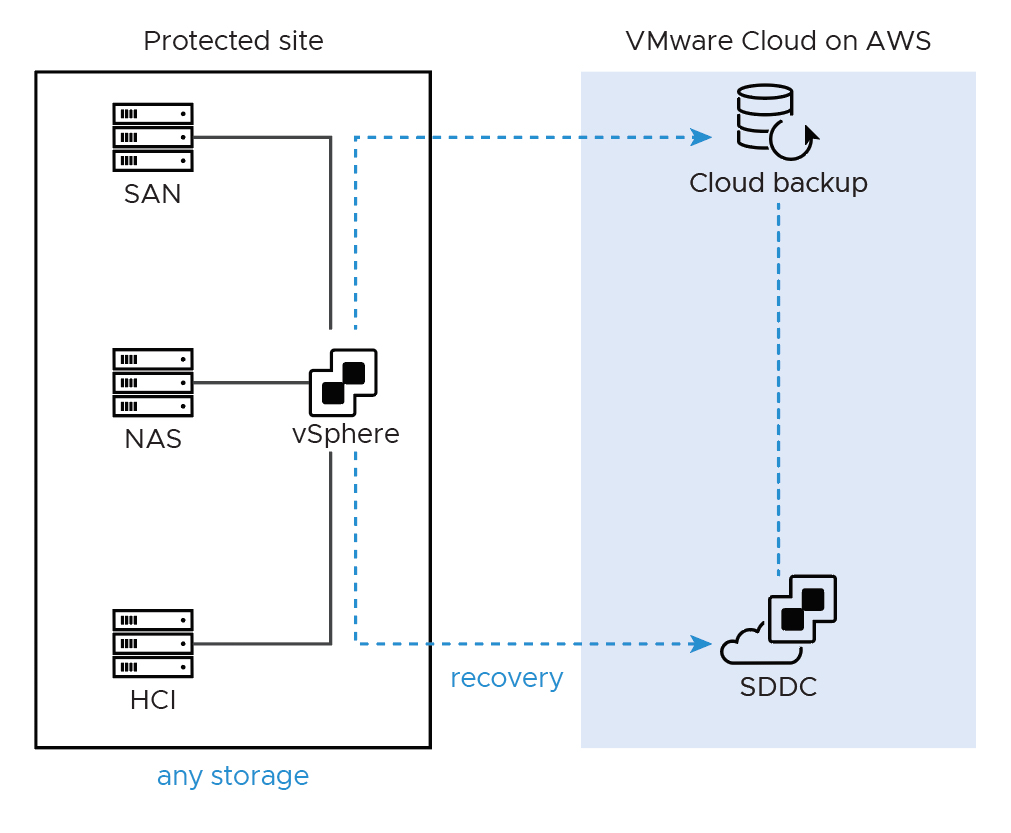
WIth more complex architectures, it often makes sense to consider a mixed DR scenario. In these cases, moving some of the applications to the VMC on AWS environment to run permanently, or leveraging another method for replicating outside the traditional VCDR SaaS orchestrator may be warranted. While this does present some risk again since this is not tested with the rest of the VCDR environment, it does provide for additional options.
With the recent addition of Cloud to Cloud DR, more options were made available for complex disaster recovery solutions. Once an environment has been migrated full time to VMC on AWS, VCDR can be leveraged as a cost effective backup solution between reasons without a need to refactor applications.
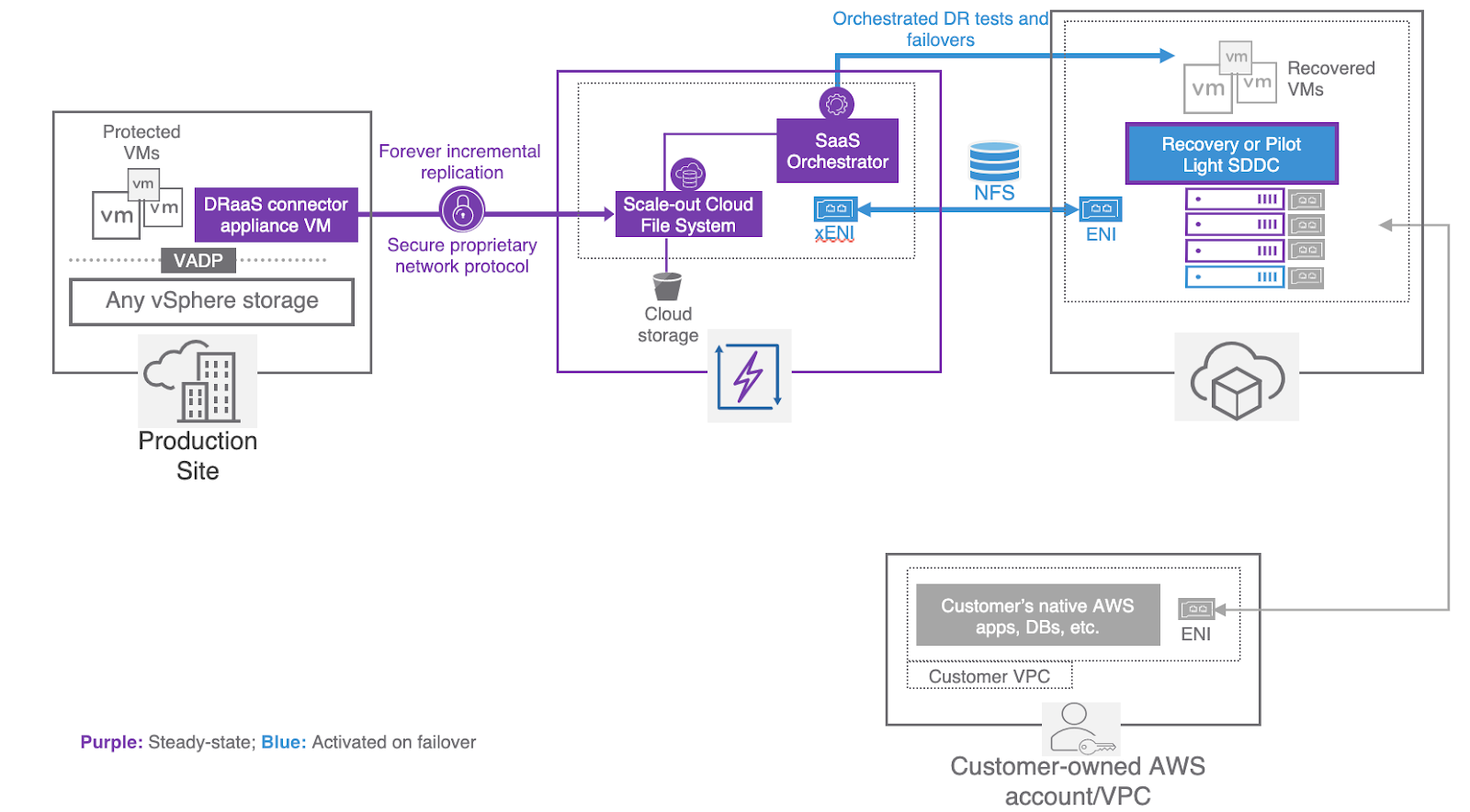
Even in advanced DR scenarios, the VCDR solution is one of the more cost effective and user friendly available. With the simplicity of the VMC on AWS cloud based interface, and policy based protection and recovery plans, even more complex environments can take advantage of the automated testing and low management overhead. The best and most impactful DR solution is the one which is tested and which will successful recover in the event it is needed.