In November of 2020, I changed roles at VMware to join the VMware Cloud on AWS team as a Cloud Solutions Architect. Going forward, I intend to work on a few posts related to the VMware Cloud product set, and cloud architecture. I am a perpetual learner, so this is my way of sharing what I am working on. I welcome comments and feedback as I share. Many of the graphics in this post were taken from the VMware VCDR Documentation.
To start with I wanted to focus on VCDR (VMware Cloud Disaster Recovery), based on the Datrium acquisition. To be clear, this is not marketing fluff, this is not a corporate perspective, this is my personal opinion based on the time I have spent working with VMware customers on the VCDR product. I promise you this may sound like marketecture, but this article lays the important foundation for the next several.
The Problem
DR (Disaster Recovery) is not an exciting topic. It is basically the equivalent to buying life insurance; you know you should do it, but usually it is a low priority, until it isn’t. We often think of disasters as fire, flood, earthquake, and other natural disasters, but recently malware has become the largest problem requiring a good DR plan.
When a system, or systems, are compromised, it is likely that not only the file systems are compromised, but also the backups, mount points, and even the DR location. Prevention is the best way to solve this issue, but assuming you are attacked, a good DR plan is critical to restoring services quickly and securely.
The Overview
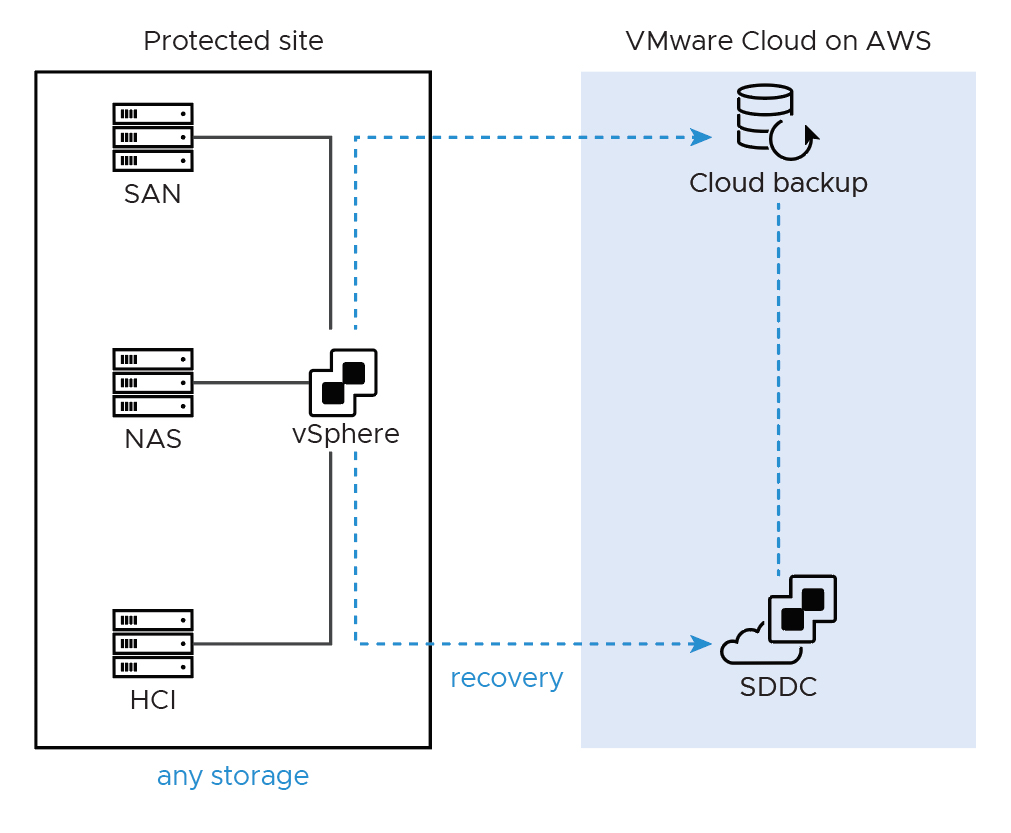
VCDR uniquely solves this problem with immutable (read only/unchangeable) backups and continuous automated compliance checking.
The biggest challenge is that when we do backups we are generally appending changed blocks which makes for a far more efficient backup solution. This lowers the cost, and the time to backup while still providing a point in time recovery solution. When the backup is compromised, the best case in this option is to go back to a time before there was malware, assuming it is not infected somehow.
VCDR solves this problem by creating an immutable point in time copy of the data. Since each point in time copy is isolated from the others, malware cannot infect the previous points. The system can then pull together all the partial backups to make what appears to be a full backup at any given point. Since this is all being handled as a service, recovery is near instant, and the recovery admin can recover from as many points as needed to find the best point to restore to.
As a Service

The promise of everything as a service seems like a great idea, but in practice it can create some challenges. It requires that we trust the service, and that we regularly test the service. VCDR is no exception. Because this is a part of the VMware Cloud portfolio, this enables adjacency to other VMware Cloud services, in particular VMware Cloud on AWS. Leveraging the Pilot Light service, some applications which are critical for recovery can be recovered directly to a cloud based service while the less critical services can be brought back online in the Datacenter once the problems are mitigated.
By providing a warm DR location, the costs are significantly mitigated, and by using the “as a service” model, many of the lower value tasks such as patching and server management are handled by the service owners, VMware in this case.
Some cool details

Aside from the immutable backups, the SaaS orchestrator, and the Scale-out Cloud File System provide a significant edge for many users. The SaaS orchestrator provides a simple web interface to configure production groups. Setting the protection groups by name patterns, or exclusion lists gives DR admins a simple setup, and no need to recover an onsite system, or log into a new site before doing recovery.
The Scale-out Cloud File System is simply an object store which provides for far greater scale, as the name implies. For instant power on to test virtual machines, this cloud based file system will mitigate the need for the additional configuration during a declared disaster. Once the appropriate recovery point is identified, simply migrate the powered on Virtual Machine back to the datacenter, or run it in the Pilot Light environment in VMC on AWS while the host is being prepared to receive the recovered VM.
Moving forward I will explore test cases for the VCDR service, where it fits within the Backup, Site Recovery Manager/Site Recovery service continuum, and even dig into the VMware Cloud on AWS services.
[…] the previous post, I talked about the VCDR (VMware Cloud Disaster Recovery) solution overview. The best way to determine if a solution is the right fit is to validate the solution in a […]